It’s a new school year, and my senior year, so of course I decided that the most reasonable course of action was to put together a new team to build a new game in a new custom engine. And I’d heavily rebuild my rendering system, too! I’m smart like that. And with new work come new posts, so aren’t you all just so lucky? Also, this post should have been made last Thursday as I’ve made pretty major strides since the information I’m about to talk about, but… school.
At the end of last year I was fairly happy with what I had accomplished, but there were also a lot of things I wanted to add and/or fix that I just never found the time for. Story of everyone’s life. My initial work has targeted two major refactor issues that are unsurprisingly intertwined: making the renderer a standalone library and multithreading.
Two years ago, I saw Reggie Meisler give a talk to Game Engine Architecture Club about a basic render-thread system in DX9 (sorry, I don’t have a link to the slides offhand) and it got me started thinking. Then last year at GDC, I saw a great talk by Bryan Dudash about utilizing deferred contexts in DX11 and the gears really started turning. I quickly realized that I could combine the knowledge from those two talks into my existing framework and get a lot of benefit, but I also knew that the messy interface (or lack thereof really) into my renderer prevented me from realistically ensuring thread-safety. And that’s why that never happened last year.
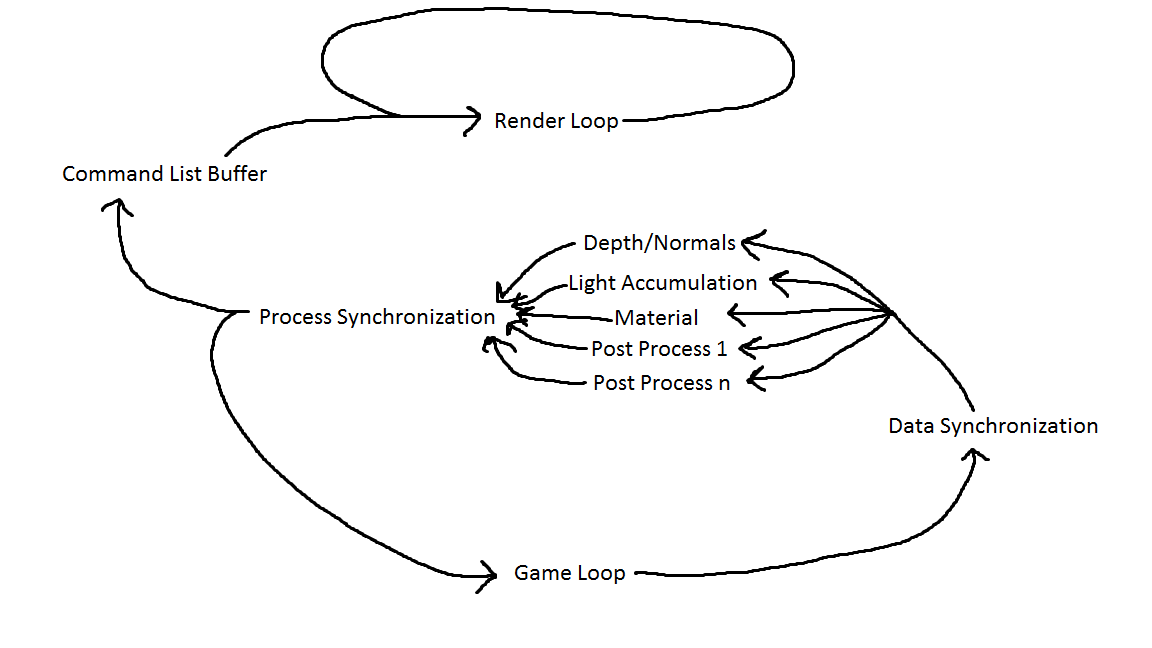
The general concept can be illustrated in this amazing diagram I drew in MS Paint.
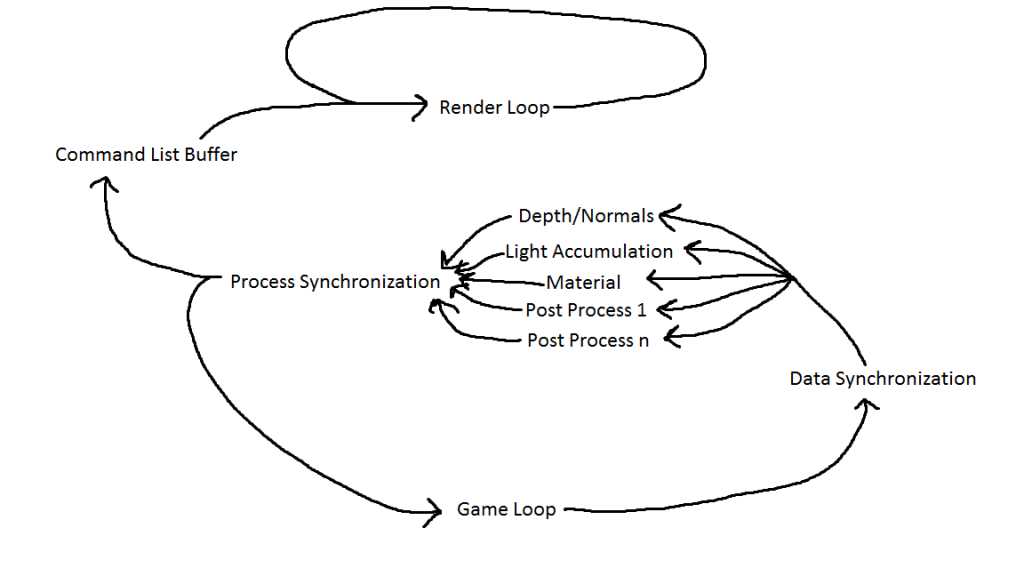
There’s two layers of parallelism in my current system, with the ability to add more later as time and performance dictate. The first layer is to put the actual rendering on a separate thread that constantly loops, consuming the last command list buffer sent to it. That was the basis of Reggie’s talk and has been a common technique for a while. The second layer is to utilize deferred contexts to build the command lists for each pass process in parallel, and is the basic implementation discussed in Bryan Dudash’s GDC presentation. Of course, currently I’m only utilizing those two layers to draw a triangle into a render target and then composite that render target into the final presentation buffer, which is super impressive and all, but it provides a successful proof of concept that I can move forward from.
GoodGraphics26.png, a triangle is reborn!
It turns out that DX11 does a pretty great job of keeping itself thread-safe as long as you don’t try to utilize a single context over two threads, so the major task in getting this working was in keeping my own data thread-safe. This necessitated three things: a simple public interface into the renderer, a transfer system for the command list buffers, and a transfer system for entities and assets. The public interface was simple once I refactored and reorganized my classes, and now allows the renderer to run as a standalone library, fulfilling one of my major initial desires with this refactor.
The command list buffer is a read/write/pivot transfer system where the gameloop side copies to the write buffer, the renderloop side copies from the read buffer, and any copy causes a swap between the target buffer and the pivot. This does introduce a lock into the system, but I used a Benaphore to keep it as lightweight as possible. Here’s the code:
/*
Project: Graphics
Purpose: Declaration of the command list buffer container
Coder/s: Matt Sutherlin (matt.sutherlin@digipen.edu)
Copyright: “All content © 2013 DigiPen (USA) Corporation, all rights reserved.”
*/
#pragma once
#include "../Definitions/ProcessEnums.hpp"
#include "../Definitions/DirectXIncludes.hpp"
#include "../Renderer/Benaphore.hpp"
struct CommandListLayer
{
CommandListLayer() {
m_bIsDirty = false;
for (unsigned lI = 0; lI < Passes::NumberOf; ++lI)
{
m_commandLists[lI] = nullptr;
}
}
~CommandListLayer() {
for (unsigned lI = 0; lI < Passes::NumberOf; ++lI)
{
SAFE_RELEASE(m_commandLists[lI]);
}
}
bool m_bIsDirty;
ID3D11CommandList* m_commandLists[Passes::NumberOf];
};
class CommandListBuffer
{
public:
CommandListBuffer() {
for (unsigned lI = 0; lI < CommandListLayers::NumberOf; ++lI)
{
m_layers[lI] = new CommandListLayer();
}
}
~CommandListBuffer() {
for (unsigned lI = 0; lI < CommandListLayers::NumberOf; ++lI)
{
delete m_layers[lI];
}
}
ID3D11CommandList** GetLayerCommandLists(CommandListLayers::Layer pLayer) {
if (pLayer == CommandListLayers::Read)
{
m_lock.Lock();
if (m_layers[CommandListLayers::Pivot]->m_bIsDirty)
{
m_layers[CommandListLayers::Read]->m_bIsDirty = false;
std::swap(m_layers[CommandListLayers::Read], m_layers[CommandListLayers::Pivot]);
}
m_lock.Unlock();
}
return m_layers[pLayer]->m_commandLists;
}
void SwapWriteLayer() {
m_lock.Lock();
m_layers[CommandListLayers::Write]->m_bIsDirty = true;
std::swap(m_layers[CommandListLayers::Write], m_layers[CommandListLayers::Pivot]);
m_lock.Unlock();
}
private:
CommandListLayer* m_layers[CommandListLayers::NumberOf];
Benaphore m_lock;
};
The entity/asset system was by far the most complicated to implement, but it came down to a single container class that enqueued data changes (add, update, or remove) until a synchronization was called. Here is the code:
/*
Project: Graphics
Purpose: Declaration of the transfer buffer container
Coder/s: Matt Sutherlin (matt.sutherlin@digipen.edu)
Copyright: “All content © 2013 DigiPen (USA) Corporation, all rights reserved.”
*/
#pragma once
#include <unordered_map>
#include <queue>
#include <type_traits>
//Q01: How does this work?
//A01: The game engine could potentially make requests for adding, removing, or
// deleting resources at any time. While the ID3D11Device is thread-free, we
// still need to be careful with resource management.
//
// Adds can create their new resources immediately (and need to do so to return
// a resource ID to the caller), but should not be added to traversal lists
// while process threads are running. So we defer that until the next game loop.
//
// Updates should only occur at the start of a new game loop, so they're deferred
// until the game thread calls for a synch. We need to ensure the data we're
// traversing doesn't get changed out from under us, so we synch this before
// producer threads start for the frame.
//
// Deletes have two levels of synchronization to deal with. Removing the resource
// from traversal lists needs to happen at the next game loop and removing it
// from memory needs to happen at the next render loop after that.
//
//Q02: What are the limitations?
//A02: t_entry objects need to have an UpdateData function, and that function needs to
// take a t_data object.
//
// t_id objects need to be able to be initialized by setting = 0, and need to
// properly increment when post-incremented.
//
// t_entry and t_data objects MUST be pointer types.
template <typename t_entry, typename t_data, typename t_id>
class TransferBuffer
{
typedef std::pair<t_id, t_entry> t_entryPair;
typedef std::pair<t_id, t_data> t_dataPair;
typedef typename std::unordered_map<t_id, t_entry>::iterator t_iterator;
private:
std::unordered_map<t_id, t_entry> m_entries;
std::queue<t_entryPair> m_pendingAdditions;
std::queue<t_id> m_markedDeletions;
std::queue<t_entry> m_pendingDeletions;
std::queue<t_dataPair> m_pendingUpdates;
t_id m_nextID;
public:
TransferBuffer() {
m_nextID = 0;
}
~TransferBuffer() {
}
//This should only ever be called by the game engine!
t_id AddEntry(t_data pData) {
t_id lReturnID = m_nextID++;
t_entry lEntry = new std::remove_pointer<t_entry>::type(pData);
m_pendingAdditions.push(t_entryPair(lReturnID, lEntry));
return lReturnID;
}
//This should only ever be called by the game engine!
void RemoveEntry(t_id pID) {
m_markedDeletions.push(pID);
}
//This should only ever be called by the game engine!
void UpdateEntry(t_id pID, t_data pData) {
t_data lData = new std::remove_pointer<t_data>::type();
memcpy(lData, pData, sizeof(std::remove_pointer<t_data>::type));
m_pendingUpdates.push(t_dataPair(pID, lData));
}
//This should only ever be called by parallel producer threads!
t_iterator GetEntries() {
return m_entries.begin();
}
t_iterator GetEnd() {
return m_entries.end();
}
//This should only ever be called by the synchronous game thread!
//Should get called once per game loop before threading deferred contexts
void SynchAdd() {
unsigned lSizeAdditions = m_pendingAdditions.size();
for (unsigned lI = 0; lI < lSizeAdditions; ++lI)
{
t_entryPair lEntryPair = m_pendingAdditions.front();
m_pendingAdditions.pop();
m_entries.emplace(lEntryPair.first, lEntryPair.second);
}
}
//This should only ever be called by the synchronous game thread!
//Should get called directly after SynchAdd
void SynchUpdate() {
unsigned lSizeUpdates = m_pendingUpdates.size();
for (unsigned lI = 0; lI < lSizeUpdates; ++lI)
{
t_dataPair lDataPair = m_pendingUpdates.front();
m_pendingUpdates.pop();
auto lIter = m_entries.find(lDataPair.first);
if (lIter != m_entries.end())
{
lIter->second->UpdateData(lDataPair.second);
delete lDataPair.second;
}
}
}
//This should only ever be called by synchronous game thread!
//Should get called directly after SynchUpdate
void SynchMarkedDelete() {
unsigned lSizeDeletions = m_markedDeletions.size();
for (unsigned lI = 0; lI < lSizeDeletions; ++lI)
{
t_id lID = m_markedDeletions.front();
m_markedDeletions.pop();
auto lIter = m_entries.find(lID);
if (lIter != m_entries.end())
{
t_entry lEntry = lIter->second;
m_pendingDeletions.push(lEntry);
m_entries.erase(lIter);
}
}
}
//This should only ever be called by the parallel consumer thread!
//Should only get called at the start of a render loop
void SynchPendingDelete() {
unsigned lSizeDeletions = m_pendingDeletions.size();
for (unsigned lI = 0; lI < lSizeDeletions; ++lI)
{
t_entry lEntry = m_pendingDeletions.front();
m_pendingDeletions.pop();
delete lEntry;
}
}
};
And that’s how I solved my big thread-safety issue. The FAQ at the top of the file is worth reading, and while I’m preplanning for t_id to be some kind of GUID functor, I’m just using unsigned int for that type in all cases right now. I welcome any questions, comments, or criticisms of my methodology, but try not to be too hard on me as this is the first time I’ve actually posted code I’ve written.
But that’s all for now. Like I said, I’ve actually managed to take the system much further in the last week, but I’m just swamped right now. Hopefully I’ll have time to make the next post before that information is also out of date, but no promises.





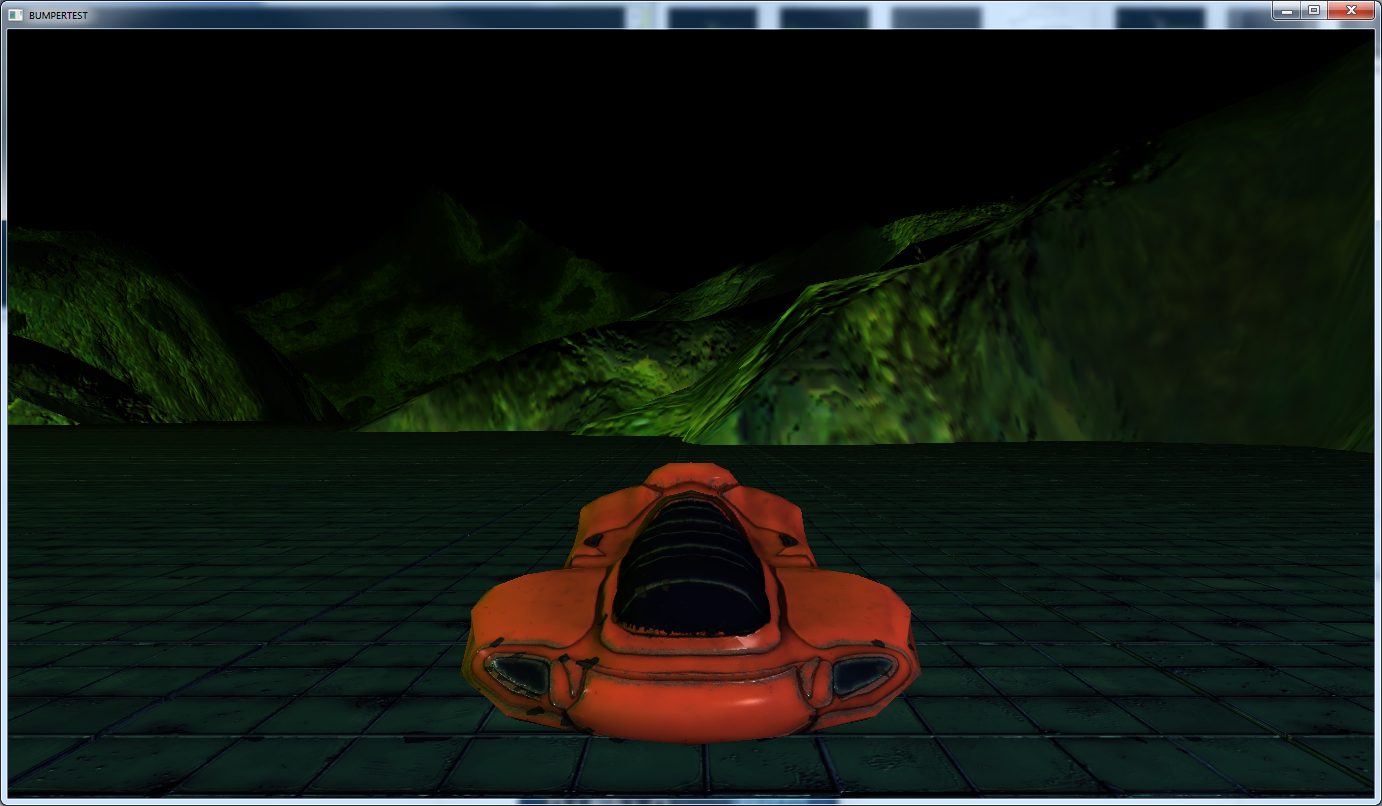
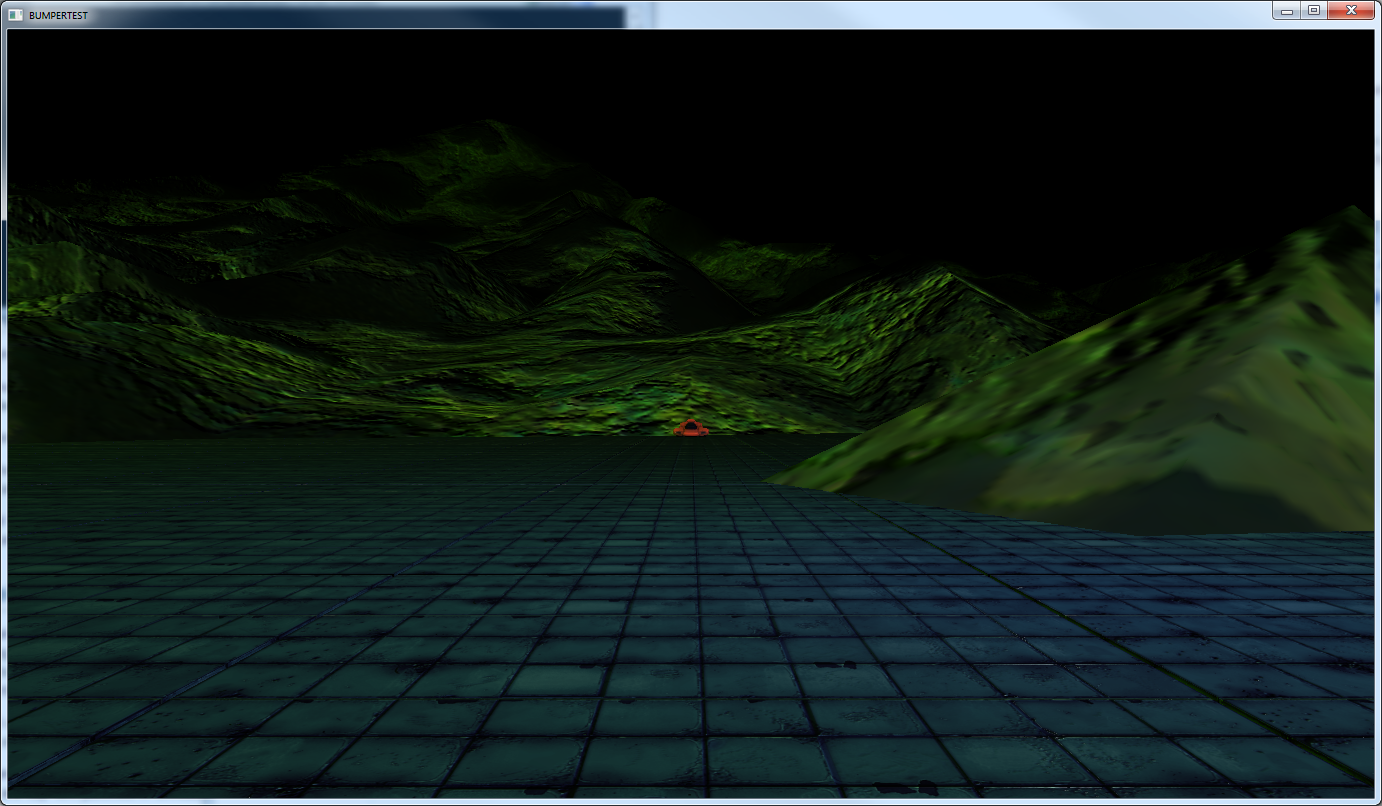 Now, unfortunately these screenshots have different terrains in them and it kind of ruins the effect of what I was trying to illustrate. But, the movement of the terrain is minuscule as the car moves out of view into the far distance. I would have retaken them to fix this inconsistency, except I’ve made dramatic changes to the lighting model that I want to save for my next post. Sorry!
Now, unfortunately these screenshots have different terrains in them and it kind of ruins the effect of what I was trying to illustrate. But, the movement of the terrain is minuscule as the car moves out of view into the far distance. I would have retaken them to fix this inconsistency, except I’ve made dramatic changes to the lighting model that I want to save for my next post. Sorry!